
相信小伙伴们都知道今冬以来范围最广、持续时间最长、影响最重的一场低温雨雪冰冻天气过程正在进行中。预计,今天安徽、江苏、浙江、湖北、湖南等地有暴雪,局地大暴雪,新增积雪深度4~8厘米,局地可达10~20厘米。此外,贵州中东部、湖南中北部、湖北东南部、江西西北部有冻雨。言归正传,天气无时无刻都在陪伴着我们,今天小编带大家利用Python网络爬虫来实现天气情况的实时采集。

此次的目标网站是绿色呼吸网。绿色呼吸网站免费提供中国环境监测总站发布的PM2.5实时数据查询,更收集分析关于PM2.5有关的一切报告和科研结论,力求以绵薄之力寻同呼吸共命运的你关注PM2.5,关注大气健康!
程序实现很简单,本次选择BeautifulSoup选择器用于匹配目标信息,如:地区、时间、AQI指数、首要污染物、PM2.5浓度、温馨提示等。需要采集的页面内容如下图所示:

绿色呼吸网天气信息
在网页源码中,目标信息存在的位置如下图所示:
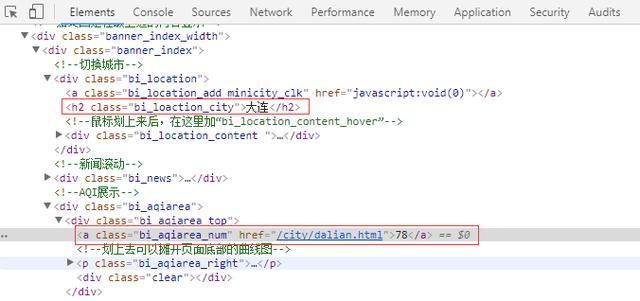
部分网页源码
在开发工具pycharm中进行代码实现,难点在于BS4选择器的语法。有个细节需要注意,部分城市在当天是没有污染物的,因此在网页中wuranwu这个属性没有任何显示,此时应该介入if判断语句,避免获取的数据为空导致程序报错,也可以做异常处理来解决这个问题。其中部分关键代码如下图所示:
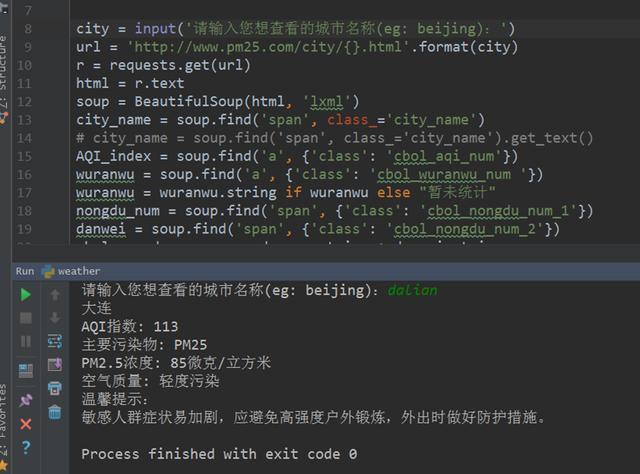
在开发工具pycharm中进行代码实现
只要我们右键点击运行,在控制台中输入我们所关注城市的汉语拼音,便可以在pycharm的控制台中可以看到该地区的实时天气信息,而且还有温馨提示,是不是很方便呢?
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
基于Python爬虫采集天气网实时信息
看: 2293次 时间:2020-06-25 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!