这是我的第一个真正意思上的自动化脚本。
1、练习的测试用例为:
打开百度首页,搜索“胡歌”,然后检索列表,有无“胡歌的新浪微博”这个链接 2、在写脚本之前,需要明确测试的步骤,具体到每个步骤需要做什么,既拆分测试场景,考虑好之后,再去写脚本。
此测试场景拆分如下:
1)启动Chrome浏览器
2)打开百度首页,https://www.baidu.com
3)定位搜索输入框,输入框元素XPath表达式://*[@id=”kw”]
4)定位搜索提交按钮(百度一下)://*[@id=”su”]
5)在搜索框输入“胡歌”,点击百度一下按钮
6)在搜索结果列表判断是否存在“胡歌的新浪微博”这个链接
7)退出浏览器,结束测试
【注】chrome获取XPath路径步骤如下:
1)在你打开的网页(如:百度首页),按F12,弹出如下窗口
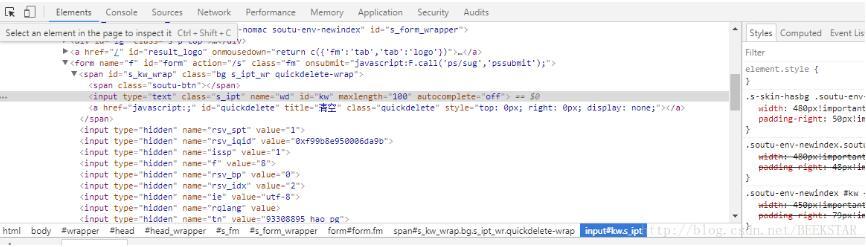
2)点击左上角箭头按钮(或Ctrl + Shift + C),此时可以在页面上移动光标,查看对应的代码,如移动到百度搜索框,显示如下:

点击一下,对应代码就会选中

然后,右击copy–>copy path 复制到XPath路径。
3、代码如下:
import time from selenium import webdriver ''' 测试用例:打开百度首页,搜索“胡歌”,然后检索列表,有无“胡歌的新浪微博”这个链接 场景拆分: 1)启动Chrome浏览器 2) 打开百度首页,https://www.baidu.com 3)定位搜索输入框,输入框元素XPath表达式://*[@id="kw"] 4)定位搜索提交按钮(百度一下)://*[@id="su"] 5)在搜索框输入“胡歌”,点击百度一下按钮 6)在搜索结果列表判断是否存在“胡歌的新浪微博”这个链接 7)退出浏览器,结束测试 ''' driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(8) # 设置隐式等待时间 driver.get("https://www.baidu.com") # 地址栏里输入网址 driver.find_element_by_xpath('//*[@id="kw"]').send_keys("胡歌") # 搜索框输入胡歌 driver.find_element_by_xpath('//*[@id="su"]').click() # 点击百度一下按钮 time.sleep(2) # 等待2秒 # 通过元素XPath来确定该元素是否显示在结果列表,从而判断“壁纸”这个链接是否显示在结果列表 # find_element_by_link_text当找不到此链接时报错,程序停止 driver.find_element_by_link_text('胡歌的新浪微博').is_displayed() driver.quit()补充知识:python + selenium自动化测试--页面操作
1、刷新当前页面
.refresh()
# 刷新当前页面
driver.refresh()2、获取本页面的URL
.current_url
用处:
一般URL可以帮助我们判断跳转的页面是否正确,或者URL中部分字段可以作为我们自动化测试脚本期待结果的一部分。
print(driver.current_url)
3、页面标题
获取当前页面标题
.title
# 获取当前页面标题显示的字段 print(driver.title)断言页面标题
# 1) 包含判断 # assert:断言,声称 try: assert "百度一下" in driver.title print("断言测试成功.") except Exception as e: print("断言失败.",format(e)) # 2) 完全相等判断 if "百度一下,你就知道" == driver.title: print("成功.") else: print("失败.") print(driver.title)4、新建标签页
用js实现如下:
try: # 新标签页,此处用js实现,在有些博客上显示使用 # driver.find_element_by_tag_name('body').send_keys(Keys.CONTROL, 't') # 我这测试无效,原因不知,于是采用如下方法 js = "window.open('http://www.acfun.cn/')" driver.execute_script(js) # 切换到新的窗口 handles = driver.window_handles # 获取窗口句柄 driver.switch_to.window(handles[-1]) # 切换到最后一个既最新打开的窗口 # 先切换窗口再打开新网址,才是在新窗口打开网址,不然还是在原来的百度页面打开此网址 driver.get('http://map.baidu.com/') except Exception as e: print("发现异常,",format(e))5、页面前进、后退
前进: .forward()
后退: .back()
driver.get("https://www.baidu.com") time.sleep(2) '''前进,后退''' elem_news = driver.find_element_by_link_text("新闻").click() # 点击进入新闻 time.sleep(2) driver.back() # 后退到百度首页 time.sleep(2) driver.forward() # 从百度前进到新闻页 time.sleep(2)6、获取浏览器版本号
.capabilities[‘version']
# 获取浏览器版本号 """ Creates a new session with the desired capabilities. :Args: - browser_name - The name of the browser to request. - version - Which browser version to request. - platform - Which platform to request the browser on. - javascript_enabled - Whether the new session should support JavaScript. - browser_profile - A selenium.webdriver.firefox.firefox_profile.FirefoxProfile object. Only used if Firefox is requested. """ print(driver.capabilities['version'])以上这篇python+Selenium自动化测试——输入,点击操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:selenium
python+Selenium自动化测试——输入,点击操作
看: 1641次 时间:2020-08-07 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!