scrapy框架简介
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
scrapy架构图
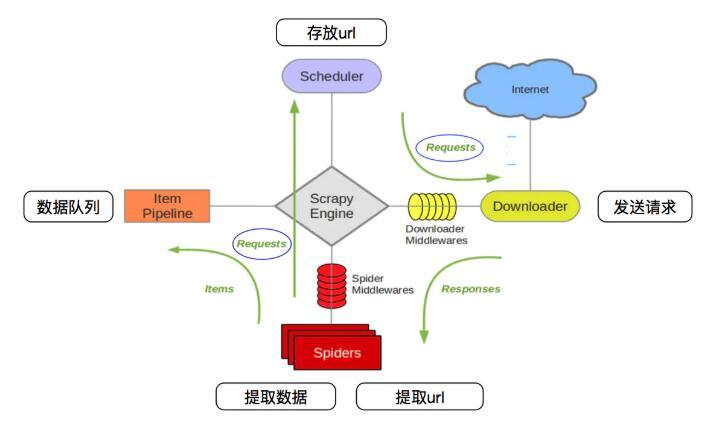
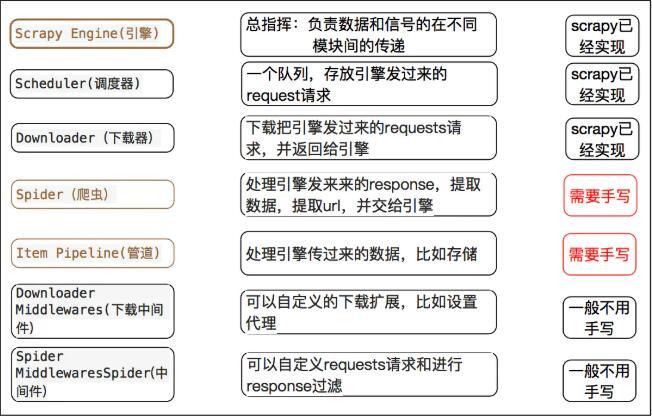
- crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
正文开始
我们知道,有的网页必须要登录才能访问其内容。scrapy登录的实现一般就三种方式。
1.在第一次请求中直接携带用户名和密码。
2.必须要访问一次目标地址,服务器返回一些参数,例如验证码,一些特定的加密字符串等,自己通过相应手段分析与提取,第二次请求时带上这些参数即可。可以参考https://www.jb51.net/article/190242.htm
3.不必花里胡哨,直接手动登录成功,然后提取出cookie,加入到访问头中即可。
本文以第三种为例,实现scrapy携带cookie访问购物车。
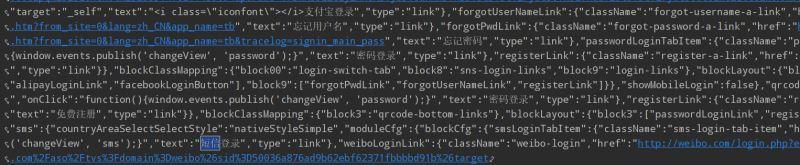
1.先手动登录自己的淘宝账号,从中提取出cookie,如下图中所示。

2.cmd中workon自己的虚拟环境,创建项目 (scrapy startproject taobao)
3.pycharm打开项目目录 ,在terminal中输入(scrapy genspider itaobao taobao.com),得到如下的目录结构

4.setting中设置相应配置
5. 在itaobao中写业务代码。我们先不加人cookie直接访问购物车,代码如下:
import scrapy class ItaobaoSpider(scrapy.Spider): name = 'itaobao' allowed_domains = ['taobao.com'] start_urls = [ 'https://cart.taobao.com/cart.htm?spm=a1z02.1.a2109.d1000367.OOeipq&nekot=1470211439694'] # 第一次就直接访问购物车 def parse(self, response): print(response.text)响应回来信息如下
明显是跳转到登录页面的意思。
6.言归正传,正确的代码如下,需要重写
start_requests()方法,此方法可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求。import scrapy class ItaobaoSpider(scrapy.Spider): name = 'itaobao' allowed_domains = ['taobao.com'] # start_urls = ['https://cart.taobao.com/cart.htm?spm=a1z02.1.a2109.d1000367.OOeipq&nekot=1470211439694'] # 需要重写start_requests方法 def start_requests(self): url = "https://cart.taobao.com/cart.htm?spm=a1z02.1.a2109.d1000367.OOeipq&nekot=1470211439694" # 此处的cookie为手动登录后从浏览器粘贴下来的值 cookie = "thw=cn; cookie2=16b0fe13709f2a71dc06ab1f15dcc97b; _tb_token_=fe3431e5fe755;" \ " _samesite_flag_=true; ubn=p; ucn=center; t=538b39347231f03177d588275aba0e2f;" \ " tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5hoqmmiKd74AJ%2Bt%2FNCZ%" \ "2FSIX9GYWSRq4bvicaWHhDMtcR6rWsf0P6XW5ZT%2FgUec9VF0Ei7JzUpsghuwA4cBMNO9EHkGK53r%" \ "2Bb%2BiCEx98Frg5tzE52811c%2BnDmTNlzc2ZBkbOpdYbzZUDLaBYyN9rEdp9BVnFGP1qVAAtbsnj35zfBVfe09E%" \ "2BvRfUU823q7j4IVyan1lagxILINo%2F%2FZK6omHvvHqA4cu2IaVAhy5MzzodyJhmXmOpBiz9Pg%3D%3D; " \ "cna=5c3zFvLEEkkCAW8SYSQ2GkGo; sgcookie=E3EkJ6LRpL%2FFRZIBoXfnf; unb=578051633; " \ "uc3=id2=Vvl%2F7ZJ%2BJYNu&nk2=r7kpR6Vbl9KdZe14&lg2=URm48syIIVrSKA%3D%3D&vt3=F8dBxGJsy36E3EwQ%2BuQ%3D;" \ " csg=c99a3c3d; lgc=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349; cookie17=Vvl%2F7ZJ%2BJYNu;" \ " dnk=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349; skt=4257a8fa00b349a7; existShop=MTU5MzQ0MDI0MQ%3D%3D;" \ " uc4=nk4=0%40rVtT67i5o9%2Bt%2BQFc65xFQrUP0rGVA%2Fs%3D&id4=0%40VH93OXG6vzHVZgTpjCrALOFhU4I%3D;" \ " tracknick=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349; _cc_=W5iHLLyFfA%3D%3D; " \ "_l_g_=Ug%3D%3D; sg=%E8%8D%893d; _nk_=%5Cu5929%5Cu4ED9%5Cu8349%5Cu5929%5Cu4ED9%5Cu8349;" \ " cookie1=VAmiexC8JqC30wy9Q29G2%2FMPHkz4fpVNRQwNz77cpe8%3D; tfstk=cddPBI0-Kbhyfq5IB_1FRmwX4zaRClfA" \ "_qSREdGTI7eLP5PGXU5c-kQm2zd2HGhcE; mt=ci=8_1; v=0; uc1=cookie21=VFC%2FuZ9ainBZ&cookie15=VFC%2FuZ9ayeYq2g%3D%3D&cookie" \ "16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&existShop=false&pas=0&cookie14=UoTV75eLMpKbpQ%3D%3D&cart_m=0;" \ " _m_h5_tk=cbe3780ec220a82fe10e066b8184d23f_1593451560729; _m_h5_tk_enc=c332ce89f09d49c68e13db9d906c8fa3; " \ "l=eBxAcQbPQHureJEzBO5aourza7796IRb8sPzaNbMiInca6MC1hQ0PNQD5j-MRdtjgtChRe-PWBuvjdeBWN4dbNRMPhXJ_n0xnxvO.; " \ "isg=BJ2drKVLn8Ww-Ht9N195VKUWrHmXutEMHpgqKF9iKfRAFrxIJAhD3DbMRAoQ1unE" cookies = {} # 提取键值对 请求头中携带cookie必须是一个字典,所以要把原生的cookie字符串转换成cookie字典 for cookie in cookie.split(';'): key, value = cookie.split("=", 1) cookies[key] = value yield scrapy.Request(url=url, cookies=cookies, callback=self.parse) def parse(self, response): print(response.text)响应信息如下(部分片段):
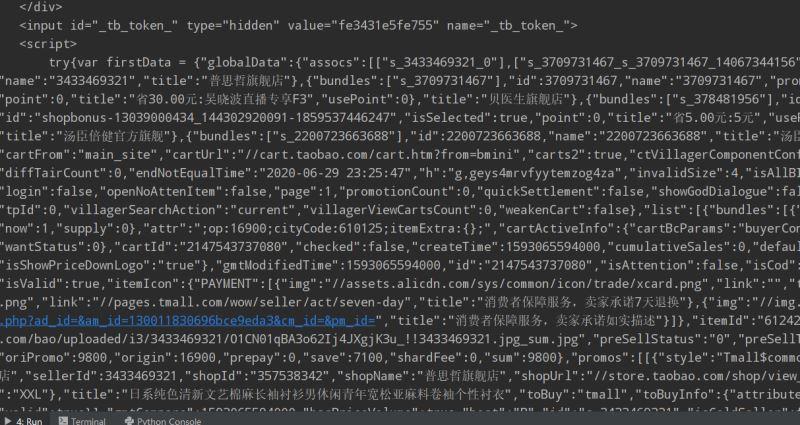
很明显这是自己购物车的真实源代码。
好了,大功告成啦,接下来就可以按照业务需求用xpath(自己喜欢用这种方式)提取自己想要的信息了。
总结
到此这篇关于scrapy框架携带cookie访问淘宝购物车的文章就介绍到这了,更多相关scrapy框架cookie内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
- << 上一篇 下一篇 >>
scrapy框架携带cookie访问淘宝购物车功能的实现代码
看: 1905次 时间:2020-08-30 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!