5月3日晚,央视在《新闻联播》前播放了B站青年宣言片《后浪》,这是B站首次登陆央视黄金时段,今天在朋友圈陆续看到相关的视频。最早用B站的同学都知道,B站是和A站以异曲同工的鬼畜视频及动漫,进入到大众视野的非主流视频网站。哔哩哔哩现为国内领先的年轻人娱乐、文化社区,该网站于2009年6月26日创建,被粉丝们亲切的称为“B站”。
B站之所以火,是因为趣味与知识并存。它是一个重度宅腐二次元集结地。B站包含动漫、漫画、游戏,也有很多由繁到简、五花八门的视频,很多冷门的软件和绘画技巧在B站都可以找到完整的教学视频。正如一句“你在B站看番,我在B站学习”,B站还是有一些质量比较好的学习视频。当你在B站上看到喜欢的视频想保存下来时,怎么办呢?
转入正题,本篇推文主要介绍如何将B站上把喜欢的视频下载下来,帮助更多需要学习的小伙伴,详细步骤如下:
- 网页分析
- 视频下载方法
- 成果展示
微信视频号的加入,再度引燃了短视频领域,今天我们爬取B站的每天播放量最多的小视频,其他类型的视频可以参考这个方法。
网页分析
网址为:
'http://vc.bilibili.com/p/eden/rank#/?tab=全部'
我们可以看到Request URL这个属性值,我们向下滑动加载视频的过程中,发现只有这段url是不变的。next_offset 会一直变化,我们可以猜测,这个可能就是获取下一个视频序号,我们只需要把这部分参数取出来,把 next_offset 写成变量值,用 JSON 的格式返回到目标网页即可。
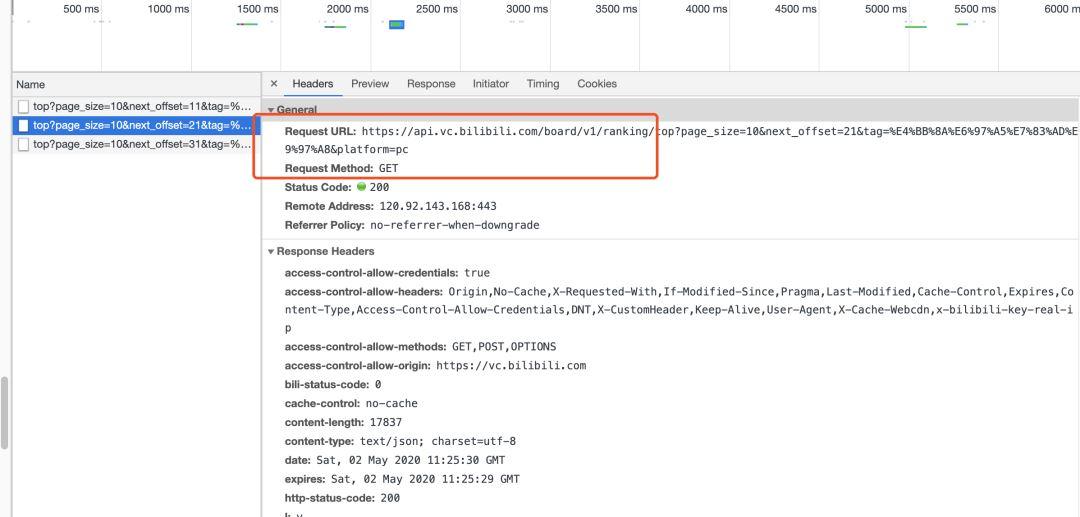
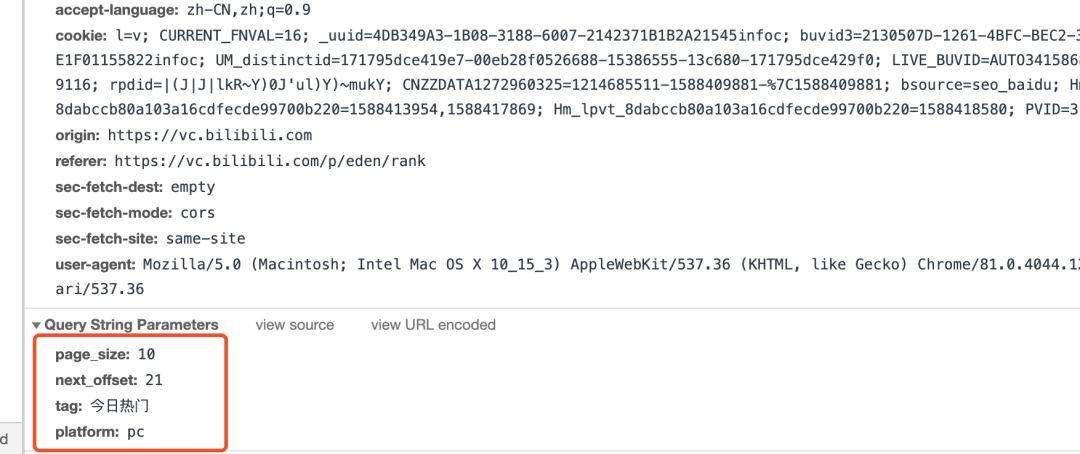
视频下载方法
上一部分已对网页进行了分析,现在我们可以利用requests.get方法来获取B站上的小视频。
核心代码
def get_json(url): headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } params = { 'page_size': 10, 'next_offset': str(num), 'tag': '今日热门', 'platform': 'pc' } try: html = requests.get(url, params=params, headers=headers) return html.json() except BaseException: print('request error') pass def download(url,path): start = time.time() # 开始时间 size = 0 headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } response = requests.get(url,headers=headers,stream=True) chunk_size = 1024 content_size = int(response.headers['content-length']) if response.status_code == 200: with open(path,'wb') as file: for data in response.iter_content(chunk_size=chunk_size): file.write(data) size += len(data)成果展示
上一部分我们已经展示了如何用Python下载视频的方法,下面我们进行效果展示

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:requests
Python如何实现爬取B站视频
看: 1878次 时间:2020-07-08 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!