场景
今天需要合并天猫订单数据,由于前期6.18活动有很多数据需要处理,将几个月份合并一起,结果报错。
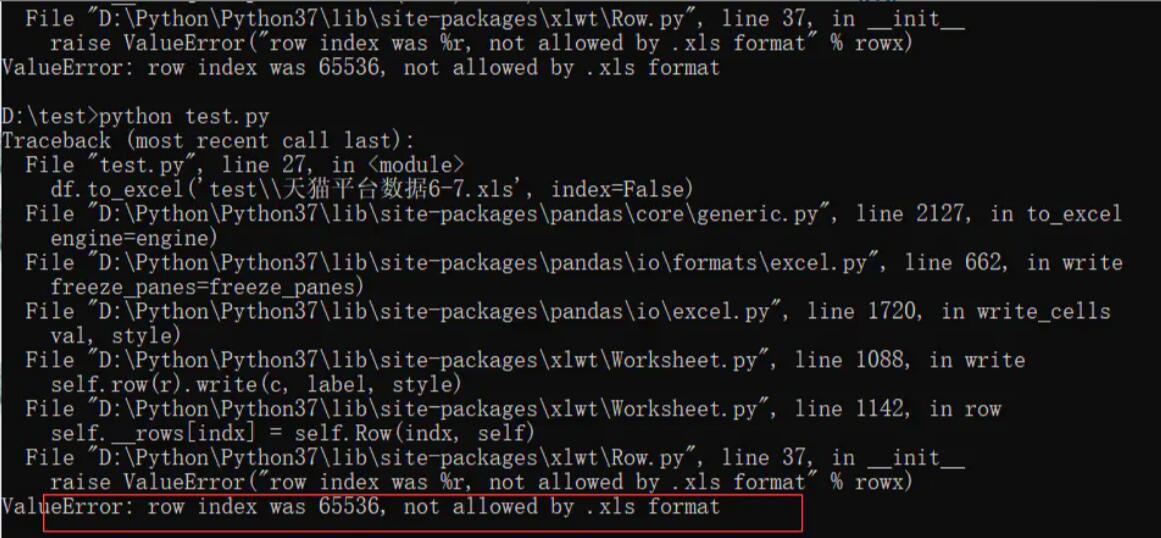
问题分析
Excel 文件的格式曾经发生过一次变化,在 Excel 2007 以前,使用扩展名为 .xls 格式的文件,这种文件格式是一种特定的二进制格式,最多支持 65,536 行,256 列表格。从 Excel 2007 版开始,默认采用了基于 XML 的新的文件格式 .xlsx ,支持的表格行数达到了 1,048,576,列数达到了 16,384。需要注意的是,将 .xlsx 格式的文件转换为 .xls 格式的文件时,65536 行和 256 列之后的数据都会被丢弃。
Pandas 读取 Excel 文件的引擎是 xlrd , xlrd 虽然同时支持 .xlsx 和 .xls 两种文件格式,但是在源码文件 xlrd/sheet.py 中限制了读取的 Excel 文件行数必须小于 65536,列数必须小于 256。
if self.biff_version >= 80: self.utter_max_rows = 65536 else: self.utter_max_rows = 16384 self.utter_max_cols = 256这就导致,即使是 .xlsx 格式的文件, xlrd 依然不支持读取 65536 行以上的 Excel 文件(源码中还有一个行数限制是 16384,这是因为 Excel 95 时代, xls 文件所支持的最大行数是 16384)。
解决办法
openpyxl 是一个专门用来操作 .xlsx 格式文件的 Python 库,和 xlrd 相比它对于最大行列数的支持和 .xlsx 文件所定义的最大行列数一致。
首先安装 openpyxl :
pip install openpyxl
Pandas 的 read_excel 方法中,有 engine 字段,可以指定所使用的处理 Excel 文件的引擎,填入 openpyxl ,再读取文件就可以了。
import os import pandas as pd # 将文件读取出来放一个列表里面 pwd = '1' # 获取文件目录 # 新建列表,存放文件名 file_list = [] # 新建列表存放每个文件数据(依次读取多个相同结构的Excel文件并创建DataFrame) dfs = [] for root,dirs,files in os.walk(pwd): # 第一个为起始路径,第二个为起始路径下的文件夹,第三个是起始路径下的文件。 for file in files: file_path = os.path.join(root, file) file_list.append(file_path) # 使用os.path.join(dirpath, name)得到全路径 df = pd.read_excel(file_path) # 导入xlsx文件,将excel转换成DataFrame dfs.append(df) # 将多个DataFrame合并为一个 df = pd.concat(dfs) # 数据输出,写入excel文件,不包含索引数据 # 数据写入 Excel,需要首先安装一个 engine,由 engine 负责将数据写入 Excel,pandas 使用 openpyx 或 xlsxwriter 作为写入引擎。 df.to_excel('test\\1.xlsx', index=False,engine='openpyxl') # 导出 Excel,一般不需要索引,将 index 参数设为 False补充知识:python使用xlrd读取excel数据作为requests的请求参数,并把返回的数据写入excel中
实现功能:
从excel中的第一列数据作为post请求的数据,数据为json格式;把post返回的结果写入到excel的第二列数据中,并把返回数据与excel中的预期结果做比较,如果与预期一致则在案例执行结果中写入成功,否则写入失败。
每一行的数据都不一样,可实现循环调用
# !/usr/bin/env python # -*- coding:utf-8 -*- #import xlwt #这个专门用于写入excel的库没有用到 import xlrd from xlutils.copy import copy import requests import json old_excel = xlrd.open_workbook('excel.xls') sheet = old_excel.sheets()[0] url = 'http://10.1.1.32:1380/service/allocFk2' headers = {'Content-Type': 'application/json'} i = 0 new_excel = copy(old_excel) for row in sheet.get_rows(): data = row[0].value response = requests.post(url=url, headers=headers, data=data) text = response.text #使用json.loads可以把Unicode类型,即json类型转换成dict类型 text = json.loads(text)["returnMsg"] #屏蔽这行代码即可把返回的完整数据写入文件中 ws = new_excel.get_sheet(0) ws.write(i,1,text) new_excel.save('excel.xls') old_excel = xlrd.open_workbook('excel.xls') new_excel = copy(old_excel) i = i+1执行前的excel格式:
发送报文 返回报文 校验字符 案例执行结果 { "projectId" :"0070", "projectAllocBatch" :"1", "serviceCode" :"GT012", "seqNo" :"180800272201GT51286712", "tranTimeStamp" :"20180817102244", "sign" :"2dbb89a6bd86b2af1ff6a76c35c05284" } 交易失败 { "projectId" :"0070", "projectAllocBatch" :"1", "serviceCode" :"GT012", "seqNo" :"180800272201GT51286713", "tranTimeStamp" :"20180817102244", "sign" :"2dbb89a6bd86b2af1ff6a76c35c05284" } 交易失败 { "projectId" :"0070", "projectAllocBatch" :"1", "serviceCode" :"GT012", "seqNo" :"180800272201GT51286713", "tranTimeStamp" :"20180817102244", "sign" :"2dbb89a6bd86b2af1ff6a76c35c05284" } 交易成功 执行后的结果:

调试过程中遇到的问题:
1、一开始在for循环的最后没有增加这两行代码
old_excel = xlrd.open_workbook('excel.xls')
new_excel = copy(old_excel)
这样的话new_excel永远都是一开始获取到的那一个,只会把最后一个循环返回的结果写入文件,因为之前的全部都被一开始获取的那个old_excel给覆盖了,所以每次执行完写入操作以后都要重新做一次copy操作,这样就能保证new_excel是最新的。
2、注意执行程序之前要把excel关闭,否则会报错
以上这篇解决使用Pandas 读取超过65536行的Excel文件问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
解决使用Pandas 读取超过65536行的Excel文件问题
看: 2049次 时间:2020-11-28 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!