项目场景:
在使用selenium模块进行数据爬取时,通常会遇到爬取iframe中的内容。会因为定位的作用域问题爬取不到数据。
问题描述:
我们以菜鸟教程的运行实例为案例。
按照正常的定位
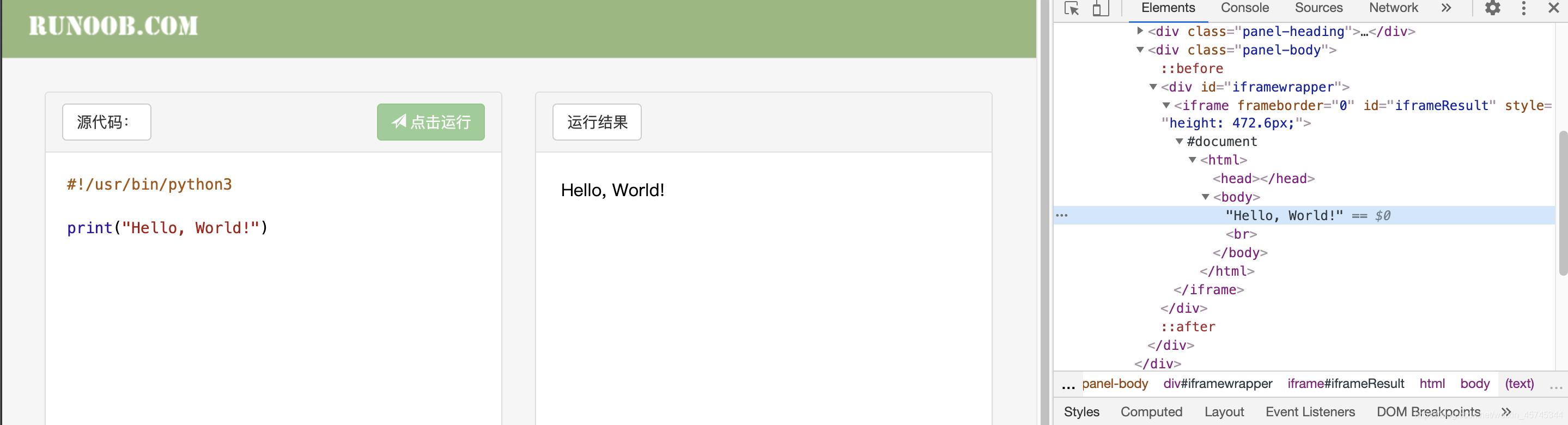
会以文本块生成xpath为/html/body/text()。这样的话根据xpath进行如下代码编写。
#!/user/bin/ # -*- coding:UTF-8 -*- # Author:Master from selenium import webdriver import time driver = webdriver.Chrome(executable_path="./chromedriver") driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3') time.sleep(2) text = driver.find_element_by_xpath('/html/body').text print(text) time.sleep(5) driver.quit()执行结果:

很明显这并不是想要的结果。
原因分析:
当我们打开抓包工具定位到Hello, World!文本的时候会发现,该文本是在一个iframe中。这样的话我们xpath所定位到的内容则是大的html中的路径。我们需要的内容则是在iframe中的小的html中。
解决方案:
通过分析发现,想要解决问题的实质就是改变作用域。通过switch_to.frame(‘id')方法来改变作用域就可以了。
重新编写代码:
#!/user/bin/ # -*- coding:UTF-8 -*- # Author:Master from selenium import webdriver import time driver = webdriver.Chrome(executable_path="./chromedriver") driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3') time.sleep(2) driver.switch_to.frame('iframeResult') text = driver.find_element_by_xpath('/html/body').text print(text) time.sleep(5) driver.quit()查看运行结果:

到此这篇关于Python爬虫实现selenium处理iframe作用域问题的文章就介绍到这了,更多相关selenium iframe作用域内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:selenium
Python爬虫实现selenium处理iframe作用域问题
看: 1664次 时间:2021-03-09 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!