三种数据抓取的方法
- 正则表达式(re库)
- BeautifulSoup(bs4)
- lxml
*利用之前构建的下载网页函数,获取目标网页的html,我们以https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/为例,获取html。
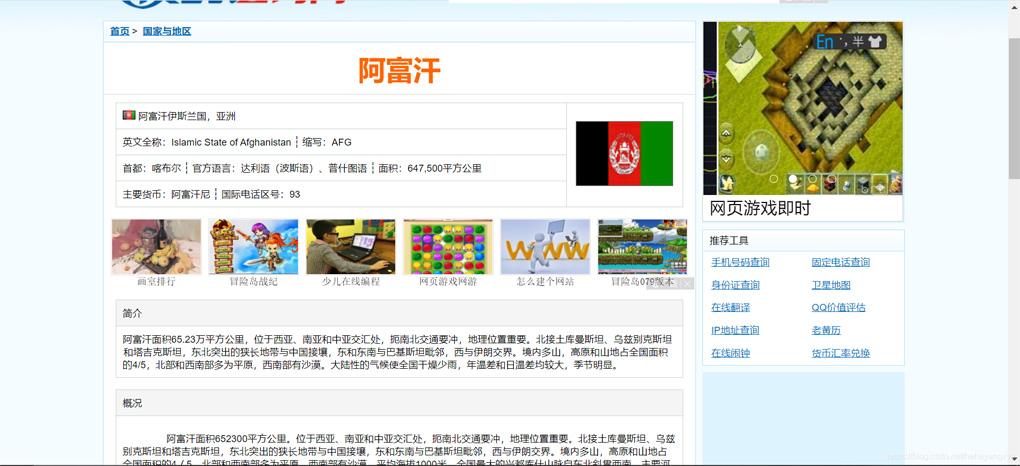
from get_html import download url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/' page_content = download(url)*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
from get_html import download import re url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/' page_content = download(url) country = re.findall('class="h2dabiaoti">(.*?)</h2>', page_content) #注意返回的是list survey_data = re.findall('<tr><td bgcolor="#FFFFFF" id="wzneirong">(.*?)</td></tr>', page_content) survey_info_list = re.findall('<p> (.*?)</p>', survey_data[0]) survey_info = ''.join(survey_info_list) print(country[0],survey_info)2.BeautifulSoup(bs4)
from get_html import download from bs4 import BeautifulSoup url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/' html = download(url) #创建 beautifulsoup 对象 soup = BeautifulSoup(html,"html.parser") #搜索 country = soup.find(attrs={'class':'h2dabiaoti'}).text survey_info = soup.find(attrs={'id':'wzneirong'}).text print(country,survey_info)3.lxml
from get_html import download from lxml import etree #解析树 url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/' page_content = download(url) selector = etree.HTML(page_content)#可进行xpath解析 country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表 for country in country_select: print(country.text) survey_select = selector.xpath('//*[@id="wzneirong"]/p') for survey_content in survey_select: print(survey_content.text,end='')运行结果:

最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:

仅供参考。
总结
到此这篇关于python数据抓取3种方法的文章就介绍到这了,更多相关python数据抓取内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
python数据抓取3种方法总结
看: 2788次 时间:2021-04-10 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!