一、配置webdriver
下载谷歌浏览器驱动,并配置好
import time import random from PIL import Image from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC if __name__ == '__main__': options = webdriver.ChromeOptions() options.binary_location = r'C:\Users\hhh\AppData\Local\Google\Chrome\Application\谷歌浏览器.exe' # driver=webdriver.Chrome(executable_path=r'D:\360Chrome\chromedriver\chromedriver.exe') driver = webdriver.Chrome(options=options) #以java模块为例 driver.get('https://www.csdn.net/nav/java') for i in range(1,20): driver.execute_script("window.scrollTo(0, document.body.scrollHeight)") time.sleep(2)二、获取URL
from bs4 import BeautifulSoup from lxml import etree html = etree.HTML(driver.page_source) # soup = BeautifulSoup(html, 'lxml') # soup_herf=soup.find_all("#feedlist_id > li:nth-child(1) > div > div > h2 > a") # soup_herf title = html.xpath('//*[@id="feedlist_id"]/li/div/div/h2/a/@href')可以看到,一下爬取了很多,速度非常快

三、写入Redis
导入redis包后,配置redis端口和redis数据库,用rpush函数写入
打开redis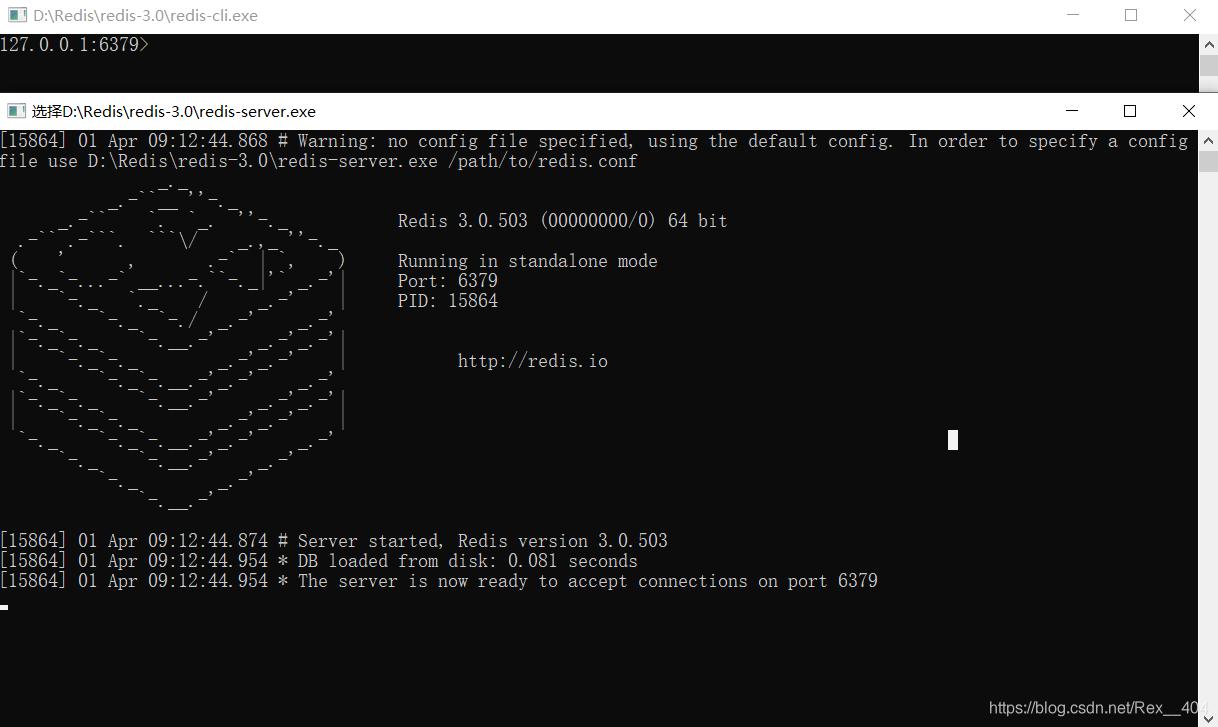
import redis r_link = redis.Redis(port='6379', host='localhost', decode_responses=True, db=1) for u in title: print("准备写入{}".format(u)) r_link.rpush("csdn_url", u) print("{}写入成功!".format(u)) print('=' * 30, '\n', "共计写入url:{}个".format(len(title)), '\n', '=' * 30)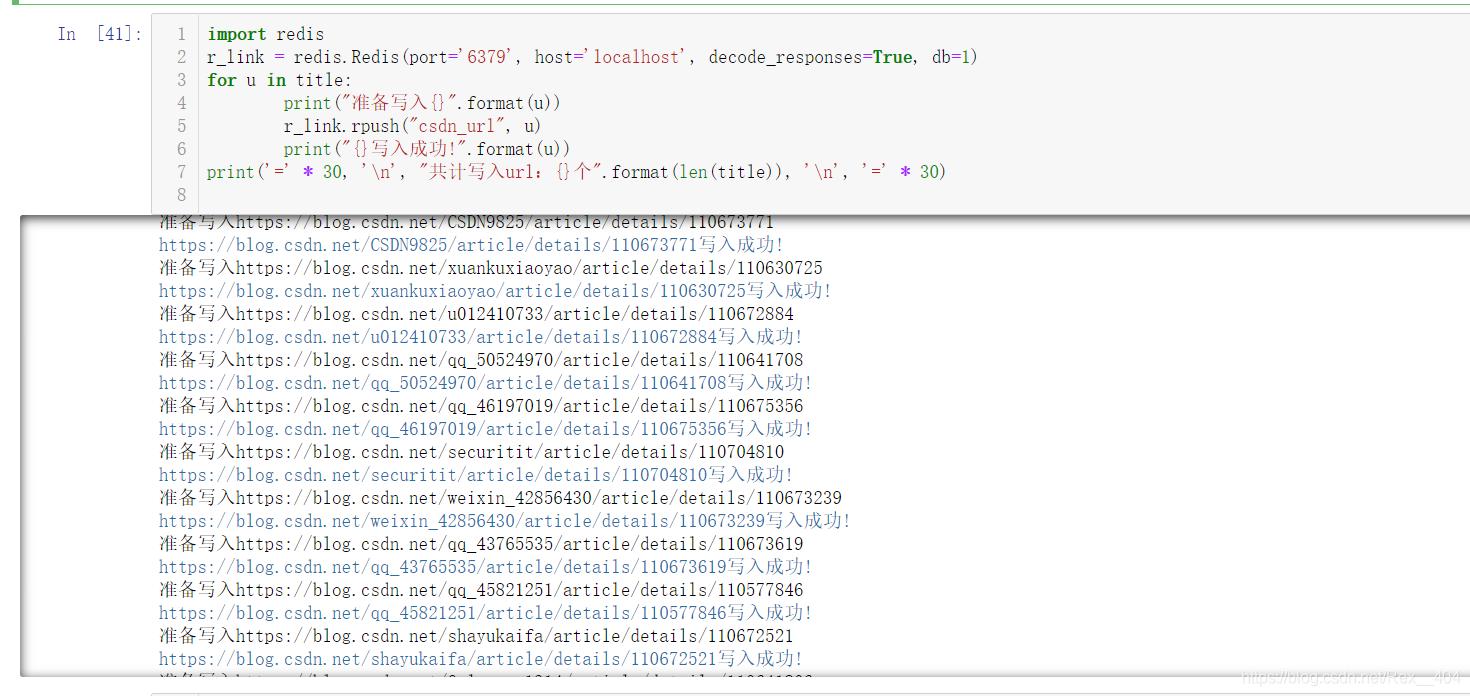
大功告成!
在Redis Desktop Manager中可以看到,爬取和写入都是非常的快。
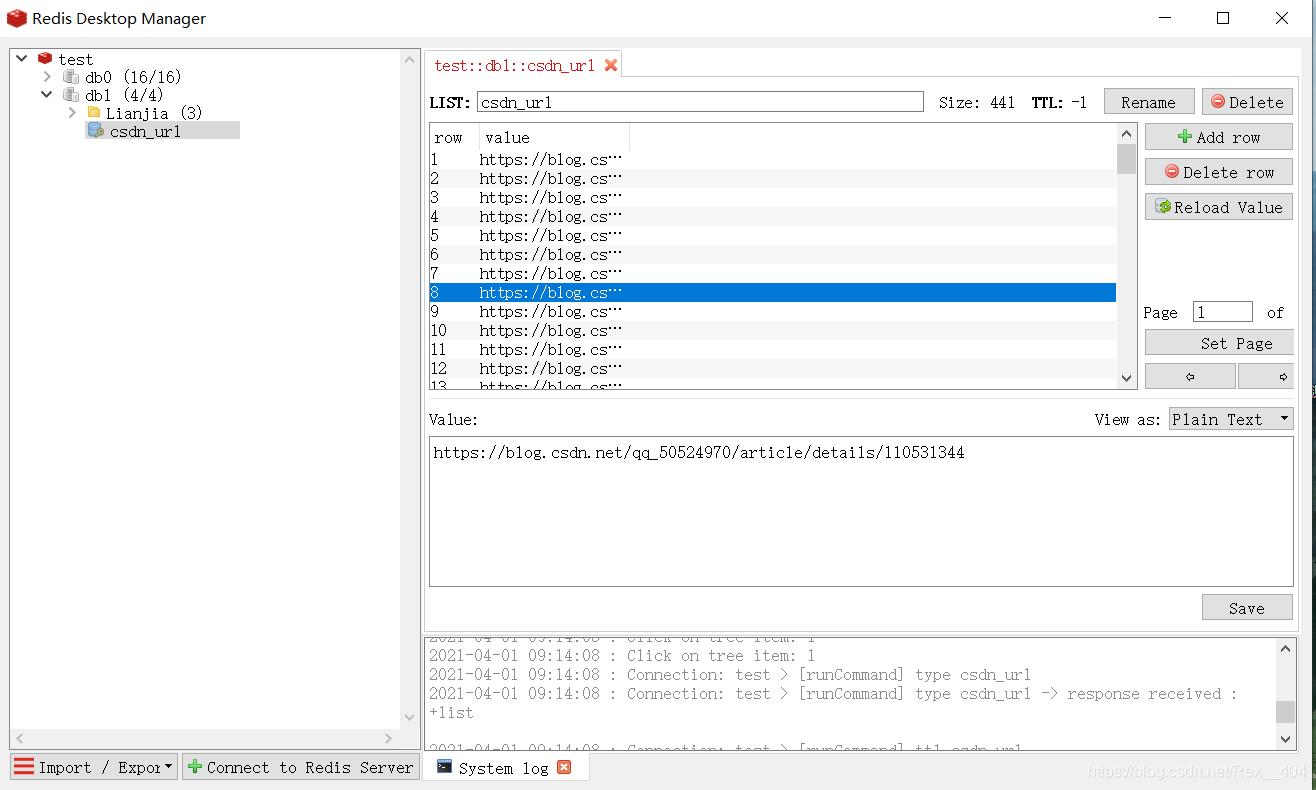
要使用只需用rpop出栈就OK
one_url = r_link.rpop("csdn_url)") while one_url: print("{}被弹出!".format(one_url))到此这篇关于详解用python实现爬取CSDN热门评论URL并存入redis的文章就介绍到这了,更多相关python爬取URL内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:selenium
详解用python实现爬取CSDN热门评论URL并存入redis
看: 2068次 时间:2021-06-04 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!