本次爬虫用到的网址是:
http://www.netbian.com/index.htm: 彼岸桌面.里面有很多的好看壁纸,而且都是可以下载高清无损的,还比较不错,所以我就拿这个网站练练手。
作为一个初学者,刚开始的时候,无论的代码的质量如何,总之代码只要能够被正确完整的运行那就很能够让自己开心的,如同我们的游戏一样,能在短时间内得到正向的反馈,我们就会更有兴趣去玩。
学习也是如此,只要我们能够在短期内得到学习带来的反馈,那么我们的对于学习的欲望也是强烈的。
作为一个菜鸡,能够完整的完整此次爬虫程序的编写,那便是一个最大的收货,但其实我在此次过程中的收获远不止此。
好的代码其实应该具有以下特性
- 能够满足最关键的需求
- 容易理解
- 有充分的注释
- 使用规范的命名
- 没有明显的安全问题
- 经过充分的测试
就以充分的测试为例,经常写代码的就应该知道,尽管多数时候你的代码没有BUG,但那仅仅说明只是大多数情况下是稳定的,但是在某些条件下就会出错(达到出错条件,存在逻辑问题的时候等)。这是肯定的。至于什么原因,不同的代码有不同的原因。如果代码程序都是一次就能完善的,那么我们使用的软件的软件就不会经常更新了。其他其中的道理就不一 一道说了,
久而自知好的代码一般具有的5大特性
1.便于维护
2.可复用
3.可扩展
4.强灵活性
5.健壮性经过我的代码运行我发现时间复杂度比较大,因此这是我将要改进的地方,但也不止于此。也有很多利用得不合理的地方,至于存在的不足的地方就待我慢慢提升改进吧!
路过的大佬欢迎留下您宝贵的代码修改意见,
完整代码如下
import os import bs4 import re import time import requests from bs4 import BeautifulSoup def getHTMLText(url, headers): """向目标服务器发起请求并返回响应""" try: r = requests.get(url=url, headers=headers) r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text, "html.parser") return soup except: return "" def CreateFolder(): """创建存储数据文件夹""" flag = True while flag == 1: file = input("请输入保存数据文件夹的名称:") if not os.path.exists(file): os.mkdir(file) flag = False else: print('该文件已存在,请重新输入') flag = True # os.path.abspath(file) 获取文件夹的绝对路径 path = os.path.abspath(file) + "\\" return path def fillUnivList(ulist, soup): """获取每一张图片的原图页面""" # [0]使得获得的ul是 <class 'bs4.BeautifulSoup'> 类型 div = soup.find_all('div', 'list')[0] for a in div('a'): if isinstance(a, bs4.element.Tag): hr = a.attrs['href'] href = re.findall(r'/desk/[1-9]\d{4}.htm', hr) if bool(href) == True: ulist.append(href[0]) return ulist def DownloadPicture(left_url,list,path): for right in list: url = left_url + right r = requests.get(url=url, timeout=10) r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text,"html.parser") tag = soup.find_all("p") # 获取img标签的alt属性,给保存图片命名 name = tag[0].a.img.attrs['alt'] img_name = name + ".jpg" # 获取图片的信息 img_src = tag[0].a.img.attrs['src'] try: img_data = requests.get(url=img_src) except: continue img_path = path + img_name with open(img_path,'wb') as fp: fp.write(img_data.content) print(img_name, " ******下载完成!") def PageNumurl(urls): num = int(input("请输入爬取所到的页码数:")) for i in range(2,num+1): u = "http://www.netbian.com/index_" + str(i) + ".htm" urls.append(u) return urls if __name__ == "__main__": uinfo = [] left_url = "http://www.netbian.com" urls = ["http://www.netbian.com/index.htm"] headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36" } start = time.time() # 1.创建保存数据的文件夹 path = CreateFolder() # 2. 确定要爬取的页面数并返回每一页的链接 PageNumurl(urls) n = int(input("访问的起始页面:")) for i in urls[n-1:]: # 3.获取每一个页面的首页数据文本 soup = getHTMLText(i, headers) # 4.访问原图所在页链接并返回图片的链接 page_list = fillUnivList(uinfo, soup) # 5.下载原图 DownloadPicture(left_url, page_list, path) print("全部下载完成!", "共" + str(len(os.listdir(path))) + "张图片") end = time.time() print("共耗时" + str(end-start) + "秒")运行
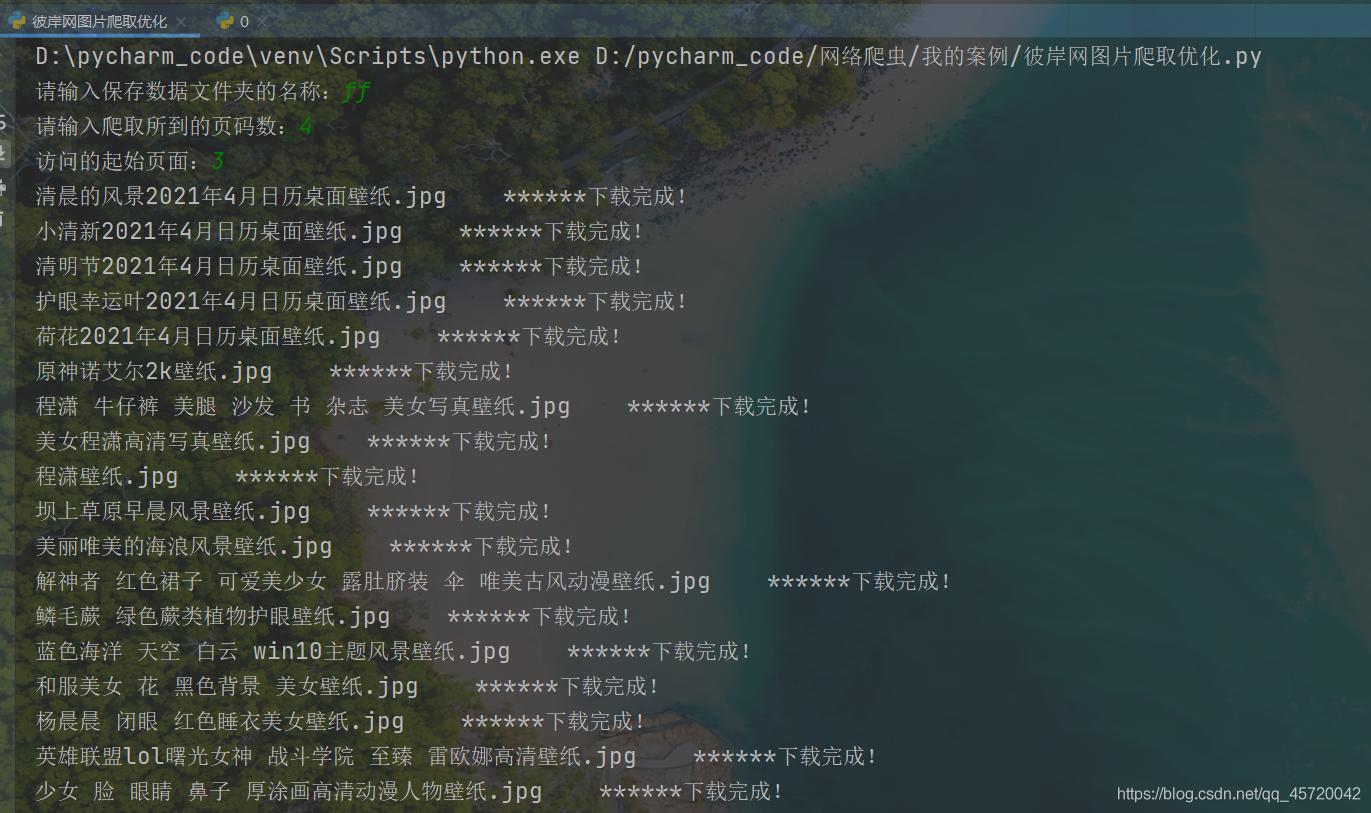
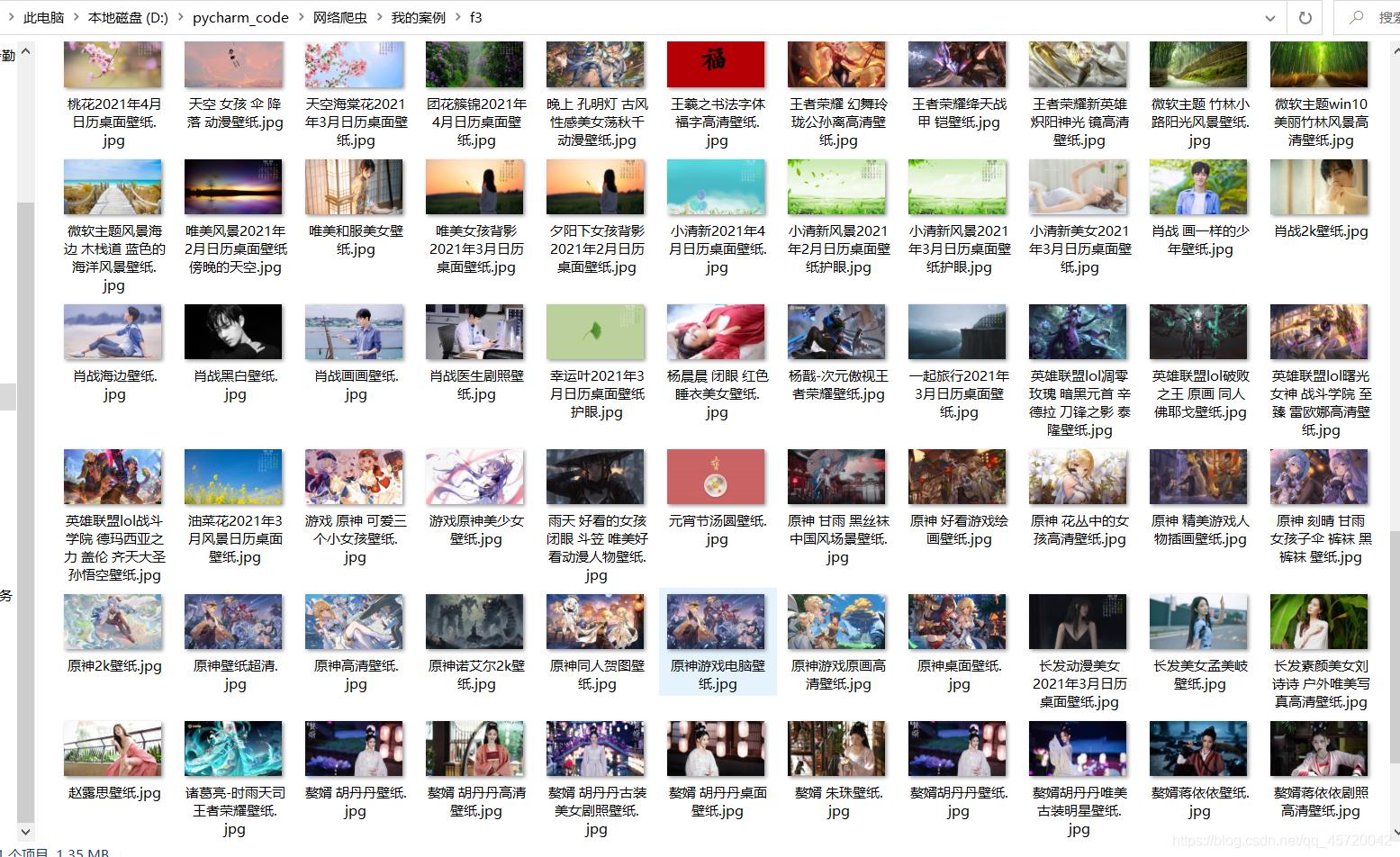
部分展示结果如下:
以上就是python 爬取壁纸网站的示例的详细内容,更多关于python 爬取壁纸网站的资料请关注python博客其它相关文章!
-
<< 上一篇 下一篇 >>
标签:requests
python 爬取壁纸网站的示例
看: 2005次 时间:2021-06-04 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!