我就废话不多说了,大家还是看代码吧!
import PyPDF2 import re pdf_file = open('xxx.pdf', mode='rb') read_pdf = PyPDF2.PdfFileReader(pdf_file) # 获取pdf文件的所有页数 number_of_pages = read_pdf.getNumPages() # print('total_page: ', number_of_pages) line_list = [] # 循环遍历每一页 for i in range(0, number_of_pages): # 读取每一页的内容 page = read_pdf.getPage(i) page_content = page.extractText() # 将这一页的内容分割为列表,,并相加所有的页面内容 line_list += page_content.split() # 关闭pdf文件 pdf_file.close() line_buf = '' for buf in line_list: line_buf = line_buf+' '+buf # 匹配数据:第一列和第二列 如:000069.sz 和 100 # print(line_buf) a = re.findall('([0-9]+[0-9]+[0-9]+[0-9]+[0-9]+[0-9]+.[a-z]+[a-z])', line_buf) b = re.findall('[0-9]+[0-9]+[0-9]+[0-9]+[0-9]+[0-9]+.[a-z]+[a-z].([0-9,]+)', line_buf) # print(b) for i in range(0, len(a)): a[i] = a[i].upper() for i in range(0, len(b)): b[i] = int(b[i].replace(',', '')) # print(b) # 组成字典 results = dict(zip(a, b))正则的其他用法:
fp = open(filename,"w") fp.write(re.search('(StockDescription:)([a-zA-Z]+-[a-zA-Z]+)',line_buf).group(2) +',') fp.write(time.strftime('%Y%m%d',time.strptime(re.search('(TradeDate:)([0-9]+[a-zA-Z]+[0-9]+)',line_buf).group(2),'%d%B%Y')) +',') fp.write(re.search('(Price:[A-Z]+)([0-9.,]+)',line_buf).group(2).replace(',','')+',') fp.close()补充知识:Logger logger = Logger.getLogger(Class clazz)获取不得的问题
因为有多个同名的Logger类,在测试的时候没注意就直接选了第一个,发现不能用,以为是JAR包的问题,重新导一遍也不能,配置文件检查过也不行,最后发现是类用错了。
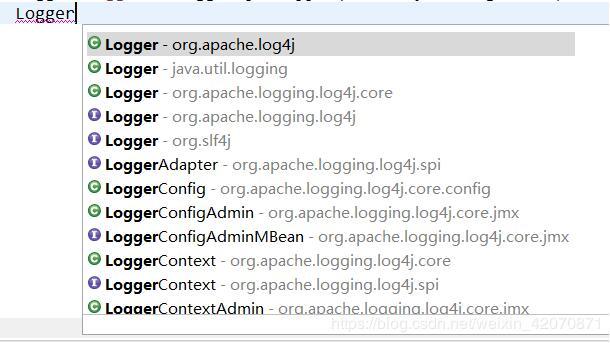
要打印日志用的是log4j包里的Logger类
以上这篇python3用PyPDF2解析pdf文件,用正则匹配数据方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
python3用PyPDF2解析pdf文件,用正则匹配数据方式
看: 1637次 时间:2020-07-09 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!