首先介绍两种编码方式硬编码和onehot编码,在模型训练所需要数据中,特征要么为连续,要么为离散特征,对于那些值为非数字的离散特征,我们要么对他们进行硬编码,要么进行onehot编码,转化为模型可以用于训练的特征
初始化一个DataFrame
import pandas as pd df = pd.DataFrame([ ['green', 'M', 20, 'class1'], ['red', 'L', 21, 'class2'], ['blue', 'XL',30, 'class3']]) df.columns = ['color', 'size', 'weight', 'class label']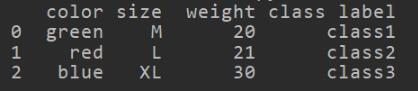
硬编码:
将feature的值从0(或者1)开始进行连续编码,比如color进行硬编码,color的值有三个,分别为编码为1,2,3
可以用如下操作,对color字段下的值进行硬编码
colorMap = {elem:index+1 for index,elem in enumerate(set(df["color"]))} df['color'] = df['color'].map(colorMap)这样可以进行硬编码了,之前我的写法是,先生成map,然后对每一行进行apply,显然没有上述代码简便
onehot编码:
将某个字段下所有值横向展开,对于每条数据,其在对应展开的值上的值就是1,听起来比较绕口,看下面的例子就知道了,python中,pandas 用get_dummies()方法即可
data1 = pd.get_dummies(df[["color"]])
如果要对多个feature 进行onehot,这样即可df[[fea1,fea2..]]
对于onehot以后的数据,如果需要原有的数据合并,直接拿原来的join onehot的数据即可
res = df.join(data1)
join操作默认是根据index来进行join的,而get_dummies()不会改变index
以上这篇pandas 中对特征进行硬编码和onehot编码的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:pandas
pandas 中对特征进行硬编码和onehot编码的实现
看: 1485次 时间:2021-01-05 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!