python web开发中http请求的处理流程通常是: web-browser , web-server , wsgi 和 web-application四个环节, 我们学习过基于bottle实现的web-application,也学习了http.server。再完成python3源码中自带的wsgiref的库,就可以拼接最后一个环节wsgi。本文会分下面几个部分:
- wsgi相关概念
- cgi示例
- wsgiref源码
- wsgi小结
- 小技巧
wsgi 相关概念
CGI
CGI(Common Gateway Interface)通用网关接口。1993年由美国NCSA(National Center for Supercomputing Applications)发明。它具有简单易用、语言无关的特点。虽然今天已经少有人直接使用CGI进行编程,但它仍被主流的Web服务器,如Apache、IIS、Nginx等广泛支持。
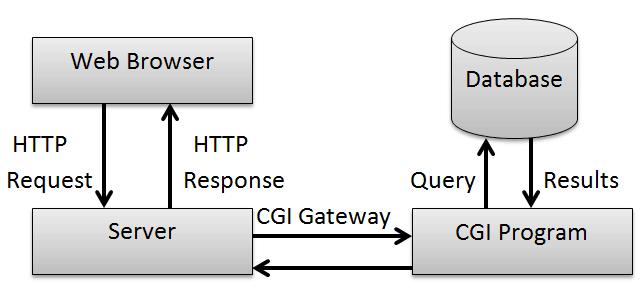
CGI提供了一种接口规范,可以让应用程序, 一般是各种脚本语言,比如perl, php, python等来扩展web服务,让服务动态起来。
WSGI
WSGI(Web Server Gateway Interface)web服务网关接口。是web服务和web应用程序之间的接口规范,在PEP3333中提出。
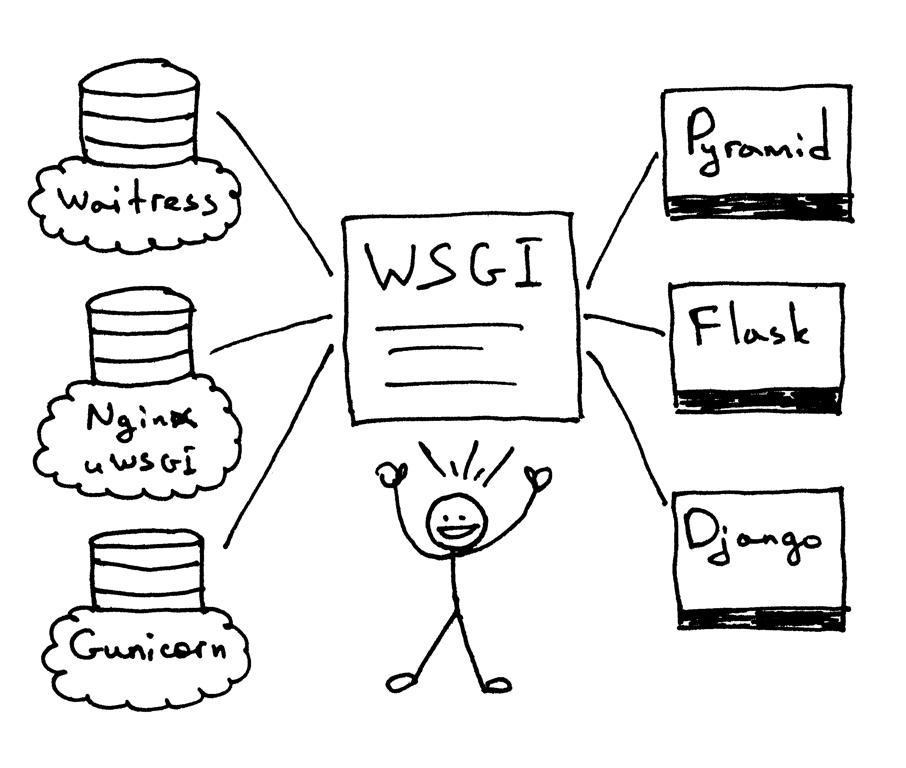
wsgi让应用程序和web服务之间解耦,应用程序只需要遵守规范,就可以在各种不同的web服务部署运行。比如上图中,基于flask/django实现的应用程序可以使用gunicorn部署,也可以使用nginx+uwsgi部署。
ASGI
ASGI(Asynchronous Server Gateway Interface) 异步服务器网关接口。ASGI继承自wsgi,旨在在具有异步功能的Python Web服务器,框架和应用程序之间提供标准接口。ASGI具有WSGI向后兼容性实现以及多个服务器和应用程序框架。
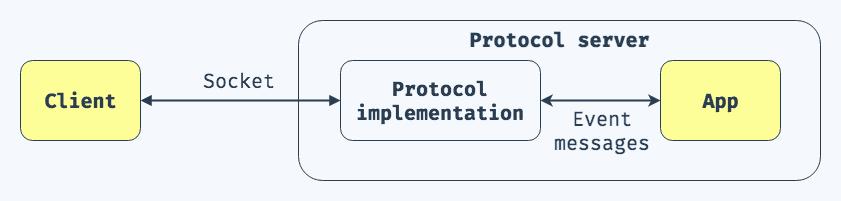
wsgi中使用请求响应模型,每个请求可以同步获得一个响应。在ASGI中,请求的响应变成异步实现,一般用于websocket协议。(asgi的内容,涉及异步实现,本文就不多介绍)
cgi 示例
单纯的概念理解比较难。下面我们配合示例一起来学习,先从CGI开始。
http 模块提供了一个简单的文件目录服务:
python3 -m http.server Serving HTTP on :: port 8000 (http://[::]:8000/) ...这个服务只有静态的展示功能,我们可以利用cgi扩展一个动态功能。
cgi脚本
创建cgi-bin目录,这是CGI中约定的目录名称。然后编写 hello.py, 代码如下:
#!/usr/bin/env python import time import sqlite3 import os DB_FILE = "guests.db" def init_db(): pass # 详情请见附件 def update_total(ts): pass # 详情请见附件 print('<html>') print('<head>') print('<meta charset="utf-8">') print('<title>Hello Word!</title>') print('</head>') print('<body>') print('<h2>Hello Python!</h2>') if not os.path.exists(DB_FILE): init_db() total = update_total(time.time()) print(f'total guest: {total}!') print('</body>') print('</html>')为了代码简洁,省略了db操作部分的具体实现。还需要给脚本可执行权限:
源码在这里
chmod 755 hello.py
./hello.py <html> <head> <meta charset="utf-8"> <title>Hello Word!</title> </head> <body> <h2>Hello Python!</h2> total guest: 4! </body> </html>启动http.server中的cgi服务:
python -m http.server --cgi注意后面的 --cgi 参数,让服务使用cgi-handler。启动后使用 curl 访问:
curl -v http://127.0.0.1:8000/cgi-bin/hello.py * Trying 127.0.0.1... * TCP_NODELAY set * Connected to 127.0.0.1 (127.0.0.1) port 8000 (#0) > GET /cgi-bin/hello.py HTTP/1.1 > Host: 127.0.0.1:8000 > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 Script output follows < Server: SimpleHTTP/0.6 Python/3.8.5 < Date: Sun, 31 Jan 2021 13:09:29 GMT < <html> < <head> < <meta charset="utf-8"> < <title>Hello Word!</title> < </head> < <body> < <h2>Hello Python!</h2> < total guest: 5! # 访客数 < </body> < </html> * Closing connection 0可以看到 hello.py 正确执行,访客数+1。因为数据存储在db中,重启服务仍然有效。
cgi服务实现
cgi的实现,主要就是下面的代码:
# http.server class CGIHTTPRequestHandler(SimpleHTTPRequestHandler): def run_cgi(self): import subprocess cmdline = [scriptfile] if self.is_python(scriptfile): interp = sys.executable cmdline = [interp, '-u'] + cmdline if '=' not in query: cmdline.append(query) try: nbytes = int(length) except (TypeError, ValueError): nbytes = 0 p = subprocess.Popen(cmdline, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env = env ) if self.command.lower() == "post" and nbytes > 0: data = self.rfile.read(nbytes) # throw away additional data [see bug #427345] while select.select([self.rfile._sock], [], [], 0)[0]: if not self.rfile._sock.recv(1): break stdout, stderr = p.communicate(data) self.wfile.write(stdout) p.stderr.close() p.stdout.close() status = p.returncode可见cgi的实现就是:
- 使用subprocess.Popen新开了一个进程去执行脚本
- 重定向脚本的输出到当前socket的wfile,也就是http请求的返回上
代码也验证了为什么需要授予 hello.py 的可执行权限。
从例子可以了解到http.server专注于提供http服务,app.py专注于业务功能,两者通过cgi进行衔接。
wsgiref
wsgiref是python自带的wsgi的实现参考(reference), 主要代码结构:
文件 描述 handlers.py wsgi实现 headers.py 管理http-header simple_server.py 支持wsgi的http服务 util.py&&validator.py 工具和验证器 WSGIServer的代码:
class WSGIServer(HTTPServer): """BaseHTTPServer that implements the Python WSGI protocol""" application = None def server_bind(self): """Override server_bind to store the server name.""" HTTPServer.server_bind(self) self.setup_environ() def setup_environ(self): # 初始化环境变量 # Set up base environment env = self.base_environ = {} env['SERVER_NAME'] = self.server_name env['GATEWAY_INTERFACE'] = 'CGI/1.1' env['SERVER_PORT'] = str(self.server_port) env['REMOTE_HOST']='' env['CONTENT_LENGTH']='' env['SCRIPT_NAME'] = '' def get_app(self): return self.application def set_app(self,application): # 注入application的class,注意是class self.application = applicationWSGIServer并不复杂,继承自http-server,接受application注入,就把web-server和we-application衔接起来。衔接后的动作,则是老规矩,交给HTTPRequestHandler去实现。同时wsgi服务多了一个准备env的动作,约定了一些wsgi的环境变量。
class WSGIRequestHandler(BaseHTTPRequestHandler): server_version = "WSGIServer/" + __version__ def get_environ(self): pass def handle(self): """Handle a single HTTP request""" self.raw_requestline = self.rfile.readline(65537) if len(self.raw_requestline) > 65536: ... self.send_error(414) return if not self.parse_request(): # An error code has been sent, just exit return handler = ServerHandler( self.rfile, self.wfile, self.get_stderr(), self.get_environ(), multithread=False, ) # 创建新的业务handler handler.request_handler = self handler.run(self.server.get_app()) # 创建application对象WSGIRequestHandler覆盖了handler,处理完成http协议(parse_request)后, 又做了四个动作:
- 创建environ
- 创建ServerHandler对象
- 创建app对象
- 运行app
environ处理主要是把http请求的header信息附带在wsgi-server的环境变量上:
def get_environ(self): env = self.server.base_environ.copy() # wsgi-server的环境变量 env['SERVER_PROTOCOL'] = self.request_version env['SERVER_SOFTWARE'] = self.server_version env['REQUEST_METHOD'] = self.command ... host = self.address_string() if host != self.client_address[0]: env['REMOTE_HOST'] = host env['REMOTE_ADDR'] = self.client_address[0] if self.headers.get('content-type') is None: env['CONTENT_TYPE'] = self.headers.get_content_type() else: env['CONTENT_TYPE'] = self.headers['content-type'] length = self.headers.get('content-length') if length: env['CONTENT_LENGTH'] = length for k, v in self.headers.items(): k=k.replace('-','_').upper(); v=v.strip() if k in env: continue # skip content length, type,etc. if 'HTTP_'+k in env: env['HTTP_'+k] += ','+v # comma-separate multiple headers else: env['HTTP_'+k] = v return envServerHandler对象的创建,接受输入/输出/错误,以及环境变量信息:
class ServerHandler(BaseHandler): def __init__(self,stdin,stdout,stderr,environ, multithread=True, multiprocess=False ): self.stdin = stdin self.stdout = stdout self.stderr = stderr self.base_env = environ self.wsgi_multithread = multithread self.wsgi_multiprocess = multiprocess ...重点在ServerHandler的run函数:
class BaseHandler: def run(self, application): """Invoke the application""" # Note to self: don't move the close()! Asynchronous servers shouldn't # call close() from finish_response(), so if you close() anywhere but # the double-error branch here, you'll break asynchronous servers by # prematurely closing. Async servers must return from 'run()' without # closing if there might still be output to iterate over. ... self.setup_environ() self.result = application(self.environ, self.start_response) self.finish_response() ...关键的3个步骤:
- setup_environ 继续构建环境变量
- 接受application处理http请求的返回
- 完成http响应
setup_environ对env进行了进一步的包装,附带了请求的in/error,这样让使用env就可以对http请求进行读写。
def setup_environ(self): """Set up the environment for one request""" env = self.environ = self.os_environ.copy() self.add_cgi_vars() # 子类实现 self.environ.update(self.base_env) env['wsgi.input'] = self.get_stdin() # 注意没有stdout env['wsgi.errors'] = self.get_stderr() env['wsgi.version'] = self.wsgi_version env['wsgi.run_once'] = self.wsgi_run_once env['wsgi.url_scheme'] = self.get_scheme() env['wsgi.multithread'] = self.wsgi_multithread env['wsgi.multiprocess'] = self.wsgi_multiprocess if self.wsgi_file_wrapper is not None: env['wsgi.file_wrapper'] = self.wsgi_file_wrapper if self.origin_server and self.server_software: env.setdefault('SERVER_SOFTWARE',self.server_software)env的处理过程,可以理解成3步:1)附加server的运行信息 2)附加请求的http头(协议信息) 3)附加请求的流信息。env,可以换个说法就是http请求的所有上下文环境。
application还接收一个回调函数start_response,主要是按照http协议的规范,生成响应状态和response_header:
def start_response(self, status, headers,exc_info=None): """'start_response()' callable as specified by PEP 3333""" self.status = status self.headers = self.headers_class(headers) status = self._convert_string_type(status, "Status") assert len(status)>=4,"Status must be at least 4 characters" assert status[:3].isdigit(), "Status message must begin w/3-digit code" assert status[3]==" ", "Status message must have a space after code" return self.writeapplication对请求的处理:
def demo_app(environ,start_response): from io import StringIO stdout = StringIO() print("Hello world!", file=stdout) print(file=stdout) # http请求及环境 h = sorted(environ.items()) for k,v in h: print(k,'=',repr(v), file=stdout) # 回调写入http_status, response_headers start_response("200 OK", [('Content-Type','text/plain; charset=utf-8')]) # 返回处理结果response_body return [stdout.getvalue().encode("utf-8")]响应仍然由ServerHandler写入:
def finish_response(self): if not self.result_is_file() or not self.sendfile(): for data in self.result: self.write(data) self.finish_content()可以使用下面命令测试这个流程:
python -m wsgiref.simple_server Serving HTTP on 0.0.0.0 port 8000 ... 127.0.0.1 - - [31/Jan/2021 21:43:05] "GET /xyz?abc HTTP/1.1" 200 3338wsgi 小结
简单小结wsgi的实现。在http请求的处理流程web-browser <-> web-server <-> wsgi <-> web-application中,体现了分层的思想,每层做不同的事情:
- web-server处理http/tcp协议,线程/进程的调度等底层实现
- wsgi承上启下,接受http请求,调用applicaiton处理请求,完成响应
- application处理上层业务逻辑
小技巧
在wsgiref代码中一样有各种小的技巧, 学习后可以让我们的代码更pythonic。
环境变量都这样设置:
def setup_environ(self): # Set up base environment env = self.base_environ = {} env['SERVER_NAME'] = self.server_name env['GATEWAY_INTERFACE'] = 'CGI/1.1' ...我之前大概都是这样写:
def setup_environ(self): self.base_environ = {} self.base_environ['SERVER_NAME'] = self.server_name self.base_environ['GATEWAY_INTERFACE'] = 'CGI/1.1'对比后,可以发现前面的写法更简洁一些。
比如流的持续写入:
def _write(self,data): result = self.stdout.write(data) if result is None or result == len(data): return from warnings import warn warn("SimpleHandler.stdout.write() should not do partial writes", DeprecationWarning) while True: data = data[result:] # 持续的写入,直到完成 if not data: break result = self.stdout.write(data)比如header的处理,实际上是把数组当作字典使用:
class Headers: """Manage a collection of HTTP response headers""" def __init__(self, headers=None): headers = headers if headers is not None else [] self._headers = headers # 内部存储使用数组 def __setitem__(self, name, val): """Set the value of a header.""" del self[name] self._headers.append( (self._convert_string_type(name), self._convert_string_type(val))) .... def __getitem__(self,name): """Get the first header value for 'name' Return None if the header is missing instead of raising an exception. Note that if the header appeared multiple times, the first exactly which occurrence gets returned is undefined. Use getall() to get all the values matching a header field name. """ return self.get(name) def get(self,name,default=None): """Get the first header value for 'name', or return 'default'""" name = self._convert_string_type(name.lower()) for k,v in self._headers: if k.lower()==name: return v return default这样对
Content-Type: application/javascript; charset=utf-8这样的值,可以使用下面方式使用:python if self.headers.get('content-type') is None: env['CONTENT_TYPE'] = self.headers.get_content_type() else: env['CONTENT_TYPE'] = self.headers['content-type']为什么用数组,而不是用字典呢?我猜测是因为header的特性是数据多为读操作。
以上就是python wsgiref源码解析的详细内容,更多关于python wsgiref源码的资料请关注python博客其它相关文章!
- << 上一篇 下一篇 >>
python wsgiref源码解析
看: 2967次 时间:2021-04-08 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!